使用 Visual Studio 利用 dotNet Framework 開發應用程,目前大概都會以 Unicode 為內碼,其實 VS2008 / VS2012 以及 SQL 2000 / SQL 2008 支援 Unicode 都沒有問題,所以我都總以為用 Unicode 開發就可以處理中文罕見字(如 堃、煊)等,但經實際測試發現在計算字串長度時,偶爾會有出入(不正確)。
底下的範例是利用「 」這幾個中文字測出來的。
」這幾個中文字測出來的。
」這幾個中文字測出來的。 | 中文 | 十六進制 | 十進制 |
| 𧖟 | 2759F | 161183 |
| 厵 | 53B5 | 21429 |
| 陳 | 9673 | 38515 |
| 𣡻 | 2387B | 145531 |
| 明 | 660E | 26126 |
| 𨰻 | 28C3B | 166971 |
(大部分的瀏覽器都無法直接支援第0字面以外的字型,那是因為字型檔沒有足夠的字)
不知是否有注意到有的十六進制內碼有的 4 位數字,有的 5位數字,Unicode的中文字碼點安排主要在第0平面與第2平面,其中第0平面支援 39126 字,第2字面44992字,上列中文內碼5碼者即落在第2字面上。
不知是否有注意到有的十六進制內碼有的 4 位數字,有的 5位數字,Unicode的中文字碼點安排主要在第0平面與第2平面,其中第0平面支援 39126 字,第2字面44992字,上列中文內碼5碼者即落在第2字面上。
就因為第0及第2字面的關係,在第0字面的碼點只要2Byte就能表示,但在第1字面以後的就會用4Byte表示(雖然用3Byte就夠了),所以才有人說 Unicode 有 2Byte 跟 4Byte (註:這種說法有誤,後面會提到)。
其實Unicode 是文字碼點的值,但在實際編碼上常用的有 UTF-8,UTF-16,UTF-32,所以說Unicode就是 Unicode 沒有2Byte 或 4Byte,但其編碼方式就有差別:
- UTF-8:是變動編碼,可能用 1 Byte 到6 Byte 來編碼 Unicode。
- UTF-16:也是變動編碼,可能是 2Byte 或者 4Byte。
- UTF-32:一律使用 4Byte 編碼。
Windows 自2000以後對 Unicode 的支援即採購 UTF-16的編碼格式,如果 Unicode 的碼點在65535(0xFFFF)以下者,採2Byte編碼, 大於 65536(0x10000)者,採用4Byte編碼,這樣的編碼設計其實沒有什麼不好,因為大部分的常用的中文字碼點是落在65535以內,用2Byte編碼可以節省空間。
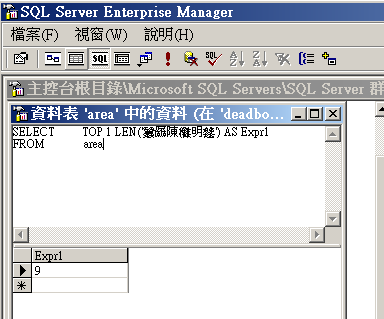
然而經測試 .NET 與 SQL 的預設字串處理採UTF-16,但內部的函數卻單純以2Byte為單位,最簡單的測試就是計算其長度,從下面的截圖會發現正確的字串長度應為 6 ,無論在 SQL 2000、SQL 2008、VS2008(.Net3.5) 或 VS2012(.Net4.5),用內建函數求得的結果卻為 9,比正確的長度多出 3個。
這會有怎樣的問題? 如果要取得 SubString 就會出現非預期的結果,例如想要取得第三個字(陳),
"疟厵陳㡻明谻".Substring(2, 1); //預期得到「陳」,結果確得到「厵」
"疟厵陳㡻明谻".Substring(4, 1); //預期得到「明」,結果確得到「□」
,而這種錯誤只在字串中含有第0字面以外的文字時才會出現,在大部分時候卻都可以運作正確無誤!
"疟厵陳㡻明谻".Substring(2, 1); //預期得到「陳」,結果確得到「厵」
"疟厵陳㡻明谻".Substring(4, 1); //預期得到「明」,結果確得到「□」
,而這種錯誤只在字串中含有第0字面以外的文字時才會出現,在大部分時候卻都可以運作正確無誤!
SQL 2000 可以處理Unicode,但對第0字面以外的字會判斷錯誤

SQL 2008 可以處理Unicode,但對第0字面以外的字會判斷錯誤

VS2008+.Net3.5 可以處理Unicode,但對第0字面以外的字會判斷錯誤

VS2012+.Net4.5 可以處理Unicode,但對第0字面以外的字照樣判斷錯誤

為了解決這個問題,只能自己撰寫字串的處理程序了,底下就是利用「擴充函數」的特性擴增字串的處理功能,利用 Len() 函數來取代 .Length 屬性,用 Substr() 函數來取代 Substring,其實運用的原理很簡單,就是先將字串都轉成 UTF-32處理完成後,使用自製的函數後,就可以正確計算長度及SubString的處理:

底下是程式碼:
#region "字串".Len();
//相當VB 的 String.Len() 用以取代 string.Length 可以計算 Unicode 第二字面的內碼
/// <summary>
/// 取得字串的長度,會先換成 UTF32再計算,可以避免第二字面的字被拆成兩組字
/// 使用方法:"字串".Len();</summary>
/// <param name="s">待處理的字串</param>
/// <returns>字串的文字個數</returns>
public static int Len(this string s)
{
return Encoding.UTF32.GetByteCount(s) / 4;
}
#endregion
#region "字串".Substr(int startIndex, int length); 用以取代 string.Substring
/// <summary>
/// 取得指定位置、長度的子字串,字串會先轉成 UTF-32
/// 使用方法:"字串".Substr(起始位置, 擷取長度);
/// 如果 startIndex 大於字數,則傳回 "" (空字串)
/// 如果 startIndex + length > 字數,則傳回由 startIndex 起之剩餘的字數
/// </summary>
/// <param name="s">待處理的字串</param>
/// <param name="startIndex">擷取的起始位置,不能大於字串長度</param>
/// <param name="length">擷取的長度,與起始位置相加,不能大於字串長度</param>
/// <returns>字串</returns>
public static string Substr(this string s, int startIndex, int length)
{
byte[] byte32Array = Encoding.UTF32.GetBytes(s);
startIndex *=4;
length *= 4;
if(startIndex >= byte32Array.Length) return "";
length = (startIndex + length) > byte32Array.Length ? byte32Array.Length- startIndex : length;
return Encoding.UTF32.GetString(byte32Array, startIndex, length);
}
/// <summary>
/// 取得指定位置起算的右方所有子字串,字串會先轉成 UTF-32
/// 使用方法:"字串".Substr(起始位置);
/// 如果 startIndex 大於字數,則傳回 "" (空字串)</summary>
/// <param name="s">待處理的字串</param>
/// <param name="startIndex">擷取的起始位置,不能大於字串長度</param>
/// <returns>字串</returns>
public static string Substr(this string s, int startIndex)
{
return s.Substr(startIndex, Int32.MaxValue);
}
#endregion
好文章,感謝分享
回覆刪除我也從別人的文章得到許多幫助,彼此分享,彼此成長,感謝您的支持
刪除感謝分享,我也是得網上前輩指引而來的。
回覆刪除果然
「為了解決這個問題,只能自己撰寫字串的處理程序了」
還是只能自己撰寫的樣子。
我目前的構想則是把所有漢字存入Access 資料表中,作為需要時的比對。效能可能不好,故有此興趣與需求。有機緣時再來向版本請教。
附上之前在別處向前輩們的討論,以見我所遘遇問題之一斑:
感謝 Albert Hsieh 前輩答覆。只是所舉例乃一般中文,當然還不成問題。(通常Big5中文字,絕無問題;一般的unicode也還好,除末附一例),可是如果您試著用CJK擴展B、C、D區的字試試,就會出錯。如,
「������」(分別是擴展B、C、D的漢字)
Dim str As String = "������"
如果您用Len()函式,或用您所用的 .Lenght 方法來試,都會發現明明只有3個中文字,可是這二個函式算出來的是長6(因為每個中文字的字元長度是2)。
像這樣,如果再用mid() 、inSri() 等函式來作處理,恐怕真要差之毫釐謬以千里了。可以想像!
是以如何判斷哪些字才是一個中文單元,成了刻不容緩的事啊。
難得得到專家達人親覆,想趁此機會請教或分享一個問題,
如「焘」「焒」二漢字雖然是一般的unicode裡的(CJK Unified Ideographs),不是擴充字集裡的,但是他倆在Access裡排序是沒法排出的來,製作不能重複的索引欄位則會出錯(重複),篩選或查詢也都同時會被篩撿出來,無法區別,也不知是何情況。試在Excel排序或篩選,好像也分不開來!南無阿彌陀佛
http://knowlet3389.blogspot.com/2012/03/vb6vbnetc.html?showComment=1410492342107#c2948983279547913449
https://plus.google.com/u/0/113855220143725210637/posts/2VtW9ReEEJ8
前所舉三個漢字果然無法正常顯示
刪除附三字之連結以供參考(其實隨舉B、C、D擴展區的漢字試驗都可以,因為B區以後的漢字全成了二個字元長的字串了)
https://www.google.com/search?q=%F0%A8%99%B8
https://www.google.com/search?q=%F0%AB%9C%A2
https://www.google.com/search?q=%F0%AB%A0%93
附帶一提本人是中文專業的,不是資訊本行,所以特別留意在漢字資訊的問題。電腦與VBA、VB全是自修自學的。請多指教,感謝先生。
對了 這裡談到16進位的漢字內碼,而我又引用了google的網路漢字碼:
刪除即
=%F0%AB%A0%93
=%F0%AB%9C%A2
=%F0%AB%A0%93
這「=」後面的字碼
這個碼的對照表,不知何處可以得?或有何方法可以取得、轉換?
這就是我講的漢字的屬性總表的建置,其中所需記錄的資料,以供任何地方使用。
如有網路碼則可在程式執行間取得正確的網址字串,以供程式無誤地執行等等...
以「%F0%AB%A0%93」為例,此為 UTF-8的編碼形式,轉成二進制碼為「11110000 10101011 10100000 10010011」,第1 byte 取右邊3碼,2~4 byte 取右邊6碼,重組得 「
刪除000 101011 100000 010011」,轉成16進制成為 「2B813」,已超出16bits範圍,是Unicode 第二字面的文字,目前windows 對Unicode 第一字面以後的文字尚無法正確處理 Len, Substring 等,只能靠自己撰寫處理函式。
(另二個字您可以自行轉換看看,應該也是第二字面的文字)
抱歉,未能立即回覆您的訊息。
請問先生這程式是C語言嗎?我只會VB。可能貼去VS揣摩試試看了。謝謝您。
刪除是 剛才才看到文章底部的標籤標 C# 應是 C# 了 早就想碰碰C或Python、Java了,正好硬著頭皮去碰了。南無阿彌陀佛
刪除的確是 C#,因為我的工作是開發網頁程式,主要的語言是 C# 和 VB.NET。
刪除VB.NET 跟 C# 除了格式不同外,大部分函式(或物件)都很相近,倒是程 VBA 有很大差別,VBA會綁應用程式(如Word)物件。
C#裡也可以使用Word物件,但執行環境必須要安裝Word,所以沒有在C#上使用Word物件。
謝謝先生如此及時地回覆,受寵若驚。感恩感恩。在貼您分享的程式碼試作時,發現這行:
刪除/// 字串的文子個數 public static int Len(this string s)
直接貼上去容易造成「public static int Len(this string s)」也成了註解文字而產生錯誤了。雖然先生已有標色以示區別,然可否請先生略加更改,以便後來初學者。(「文子」二字也請先生順便改成「文字」吧,如果末學沒理解錯誤的話。因為對一片空白的初學來說,一些小差異讀來都是很困擾、費勁的)
託先生的福,末學這兩天都在琢磨這段程式,也終於有機會正式觸碰了一下 C 語言與C#,得到先生啟示和VB.net很像,我信心大增,興趣也大增。因為自己從VBA是摸了點VB了,還買了些參考書,只是時間不允全力投注,至今仍是打帶跑一知半解爾。
我讀微軟教程:
https://msdn.microsoft.com/zh-tw/library/aa287556%28v=vs.71%29.aspx
// 雙斜線是註解,而先生都用三斜線何故呢?好像不限斜線數的樣子,
VB和VBA都是用「'」,想就是先生所謂的格式不同吧。
C#從零自修,不知先生有何好的入門書可以推薦末學從頭來自修的,感謝感謝。多所叨擾,還望先生見諒。南無阿彌陀佛
一、感謝指正,我已更正程式碼及註解分行的問題。
刪除二、 C# 的註解方式有三種,如下:
在 C# 裡 //(雙鈄線)是單行註解,表示從 // 之後到換行符號之間的文字都是註解
/* */ 是段落註解,可以跨多行,從 /* 之後開始 到 */ 結速
/// (三鈄線)是文件註解,在Visual Studio 中直接輸入 /// 會直接顯示註解樣板,可以輸入函式(或叫方法或屬性)的功能說明、輸入引數說明及回傳值說明, /// 是有特殊意義的,可以用在自動產生文件。
三、另一種常用的大綱註解:
#region "說明文字"
#endregion
它方便撰寫程式碼時可收合,減少眼睛受到太多程式碼干擾。
希望這些說明對您有所助益。
我不知如何推薦 C# 入門書,因為我之前(10幾年前)就有 C底子,在撰寫程式時都是直接參考線上資料,所以也不曉得哪一本寫的比較好。
刪除VB.NET 與 C# 基本不同就是 VB.NET 是走BASIC風格,而 C# 是走 C/C++ 風格,但在物件(或類別)的使用方式幾乎一樣,除了 VB.NET 是用:
DIM var as CLASS 宣告
而 C# 用
CLASS var; 宣告
還有 C# 要用 { } 區分程式區塊。
其餘差異不大
沒想到事隔要3年了,今天再爬,才又發現此文。阿彌陀佛
回覆刪除感恩陳菩薩慈悲。
末學目前一直利用Word裡Characters的集合屬性來取得正確中文字串長度。但這樣就得CreateObject個Word.Applictaion來處理,光這行指定,跑起來就慢了。
……
Set wd = CreateObject("Word.Application")
'wd.UserControl = False
'Set wd = New Word.Application
Set rngd = wd.Documents.Add
Set od = wd.Documents.Add
'rngd.ActiveWindow.Visible = False
'od.ActiveWindow.Visible = False
od.Range.Text = d.Range.Text
Set rng = od.Range
For Each a In rng.Characters
……
Next a
rngd.Close wdDoNotSaveChanges
od.Close wdDoNotSaveChanges
Set rngd = Nothing
Set od = Nothing
wd.Quit wdDoNotSaveChanges
Set wd = Nothing
……
今晚心血來潮,再來搜尋看看,沒想到仍是舊帖重拾,但幾乎不復記憶了。明早再來溫習看看了。感恩感恩先生。
只是我主要是在VBA,其中倒沒有VB裡頭一些函式可用。 明天再琢磨了。先記著,並致謝。南無阿彌陀佛
關鍵應是Word Characters這個屬性是怎麼正確抓到每個中文字元的。若能理解其中作用原理,應該就OK了。
刪除目前末學取得中文字元長度最佳、最妥方式即是用 Word.ActiveDocument.Range.Characters.count 這個屬性值了。
我沒有研究過Word如何判斷中文字,我的基本想法是「任何文字在UTF-32中都是 4碼,只要將任何內碼轉成UTF-32就能計算字數」
刪除陳菩薩您好,剛才末學看到這段(搜尋時意外發現的)且文章很新:
刪除屬性代表它包含的 Char 物件數目,而非 Unicode 字元的數目。 若要存取字串中的個別 Unicode 字碼指標,請使用 物件。
https://docs.microsoft.com/zh-tw/dotnet/csharp/programming-guide/strings/
是否目前C# 已提供了「個別 Unicode 字碼指標」的解決方法?這個「 Unicode 字碼指標」的「StringInfo 物件」是否便能方便我們正確判讀包括CJK擴充字集在內的一切漢字了? 感恩感恩 南無阿彌陀佛
哈 我剛試著把網址裡zh-tw改成en-us才發現,原來中文版格式上錯了,才會出現<xref:……這樣的玩意兒
原文是:
The Length property of a string represents the number of Char objects it contains, not the number of Unicode characters. To access the individual Unicode code points in a string, use the StringInfo object.
(原來zh-tw的中文譯成「字碼指標」code points,就是「碼位」或「碼點」嘛。)
這「StringInfo」object是否是一個新的類別(class)呢?對我們現下討論的主題,有沒有幫助呢?
https://docs.microsoft.com/en-us/dotnet/api/system.globalization.stringinfo?view=netframework-4.7
我剛讀到一篇說C語言裡並沒有字串型態的變數,是否這個string也是C#新加入的成員呢?還是只是object並不是變數型態?
http://dhcp.tcgs.tc.edu.tw/c/p009.htm
再查了一下,其實VS 2008 好像就有了
StringInfo.SubstringByTextElements 方法 (Int32)
https://msdn.microsoft.com/zh-tw/library/bx3zb6dh(v=vs.110).aspx
其中這句「The zero-based index of a text element in this StringInfo object.」好像就是類似Characters這樣集合類型的物件了;也是從索引值0開始的。
Characters這個屬性,恐怕不只Word有,我用它來google發現別的好像也有用到。
先生擷取中文字串長度的方法,在需要逐字處理中文字時,或許還可行,但若有類似Characters這樣,能正確載入中文字元的集合,則逐一取出處理,似更方便了。
用先生的方法,恐怕仍須配合類似 VBA.Mid()這樣的函式逐一取出中文字元再來處理才行,就不若
For Each char in Characters
……
Next char
這樣的迴圈處理來得便捷穩當了。所以才想這個Characters的集合到底是憑什麼本事可以正確擷取到一串字串中的各個中文字元也。
剛才發現,其實
StringInfo.SubstringByTextElements 方法 (Int32, Int32)
就類似VBA的Mid()函式了嘛。
應該是從StringInfo物件這裡擷取中文字串或判斷中文字長度,而不是從String物件下,菩薩您沒提到StringInfo而只提到String;是否蹊蹺就在這個point上呢?還望菩薩您慈悲救度了。感恩感恩。
StringInfo的namespace是System.Globalization而
String.Substring的則是System
可見是二個物件類別;可能是菩薩您沒有留意有這個StringInfo物件可用,是否?但願這解了咱們共有的燃眉之急啊。末學還不能實測,只能如此演繹想當然爾了。還請菩薩您撥冗定奪示下。感恩感恩。阿彌陀佛
剛才略看了一下它的示例,其實VB也可以操作。且C#好像用console來試算也不難,我晚會兒再試看看。玩 hello world讓我大概知道怎麼寫類似的C#小程序了。
https://msdn.microsoft.com/zh-tw/library/aka44szs(v=vs.110).aspx?cs-save-lang=1&cs-lang=vb#code-snippet-2
另順帶一提:得先生用心的回覆,末學內心已有個譜了,大概就是以微軟的教程及網路相關資訊為主來自修入門先了。如上報告,可見一斑吧。感恩菩薩。南無阿彌陀佛
哈!哈!我沒有提 StringInfo 是我壓根不曉得有這個類別,感謝您的提點,剛剛試了一下,它真的可以正常處理Unicode字串,貼段程式碼供參:
刪除using System;
using System.Collections.Generic;
using System.Text;
using System.Globalization;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
string a="江湖海真棒!yes!";
string b = "𧖟厵陳𣡻明𨰻江湖海真棒!yes!";
Console.WriteLine(String.Format("字串A{0} 有 {1}字",a, a.Length)); //會顯示10字
Console.WriteLine(String.Format("字串B{0} 有 {1}字",b, b.Length)); //會顯示19字(表示有許中文字被當成2個字)
StringInfo Sa = new StringInfo(a);
StringInfo Sb = new StringInfo(b);
Console.WriteLine(String.Format("字串Info A 有 {0}字", Sa.LengthInTextElements)); //顯示10字
Console.WriteLine(String.Format("字串Info B 有 {0}字", Sb.LengthInTextElements)); //顯示 16字,
Console.WriteLine(Sb.SubstringByTextElements(4, 1)); //可以正常計算子字串
Console.ReadKey();
}
}
}
哈哈 果然解決菩薩您的心頭之患了吧 感恩感恩 末學也堪略報您熱心指引之一二了。
刪除果然「蹊蹺」就在 StringInfo Object 上,魔鬼就藏在這個「System.Globalization」細節裡,所幸「但願這解了咱們共有的燃眉之急啊」一語成讖了 ^_^ 感恩感恩 南無阿彌陀佛
末學也深有同感,有時程式難構思,就在不知道可用的物件、屬性、方法有哪些,放哪裡呢!這幾天踏破鐵鞋、想破頭腦,就是聚焦在這上頭……,終於皇天不負苦心人了。感恩感恩。
剛才才發現先生已回應了,而我方靠自己的土法來煉鋼,用了人家的示例寫了這麼一段,成功了,只可惜Console不支援擴充字集,故未能正常印出該字,在VB下我還知用Debug.print來列出,不知在C#有沒有替代的方法。剛才再試著跑,我寫的這個後半部分的條列式似乎還是錯的
using System;
using System.Globalization;
namespace ConsoleApp1
{
class Program
{
static void Main(string[] args)
{
//string mystr;
string str = "𧖟厵陳𣡻明𨰻";
//string str = ActiveDocument.Range.Text
StringInfo mystrInof = new System.Globalization.StringInfo(str);
Console.WriteLine(str.Length);
Console.WriteLine(mystrInof.LengthInTextElements);
TextElementEnumerator mystrEnum = StringInfo.GetTextElementEnumerator(str);
while (mystrEnum.MoveNext())
{
string mystr = mystrEnum.Current.ToString();
Console.WriteLine(mystr);
}
Console.ReadLine();
//StringInfo.SubstringByTextElements(int);
//System.Globalization.StringInfo.SubstringByTextElements(int, int)
//Console.WriteLine("Hello World!");
}
}
}
前半段是測長度
後半段是逐一列舉(即已類似Characters的應用了 南無阿彌陀佛)但似尚未成功。擬改寫成VB,用Debug.Print或 Word.Document.Range 來列舉出看看。
前半我主要是看到這篇,照他的寫法改寫試成的
https://recalll.co/app/?q=unicode%20-%20Are%20all%20kanji%20characters%20UTF8%203%20byte%20long?
後半則是微軟文件:http://tinyurl.com/y7vcrzlb
參考之文件,均蒐集於此,也便菩薩您參考
https://www.pinterest.com/oscarsun/%E6%BC%A2%E5%AD%97%E8%B3%87%E8%A8%8A%E8%99%95%E7%90%86/
哈哈。剛才才用心讀了先生的程式,才發現先生兩個難題都解決了。不但正確的字長,且逐字處理也OK了。只要給個計數變數 s,再用「SubstringByTextElements(s, 1)」取出即可逐字叫取了。
刪除現在末學要面對的問題則是,如何將此寫好的程式,應用在 VBA 的呼叫上呢?做成增益集?dll?或者參考引用?還是能直接改寫成VBA?。只是增益集、dll,末學如 C# 也還是白丁也。
若不勞先生清神,還望先生提點一番。感恩感恩。阿彌陀佛
剛才照您的程式碼貼上,仍然「SubstringByTextElements」會有紅曲底線,訊息如末。我剛裝的是 VS 2017 Community 是否是因為Community版的緣故?但是在物件瀏覽器裡卻找得到 SubstringByTextElements (我用學校雲端的2015 professional 版也一樣呢) using 也都跟您的一樣。不知問題出在嗷裡 先生引用「SubstringByTextElements」都沒問題嗎?
刪除嚴重性 程式碼 說明 專案 檔案 行 隱藏項目狀態
錯誤 CS1061 'StringInfo' 未包含 'SubstringByTextElements' 的定義,也找不到擴充方法 'SubstringByTextElements' 可接受類型 'StringInfo' 的第一個引數 (是否遺漏 using 指示詞或組件參考?) ConsoleApp1 c:\users\oscar\documents\visual studio 2017\Projects\ConsoleApp1\ConsoleApp1\Program.cs 20 使用中
在「物件瀏覽器」中,只有「StringInfo[mscorlib,2.0.5.0]」沒有SubstringByTextElements(int)和 SubstringByTextElements(int, int) 其他 mscorlib 2.0.0.0 、 4.0.0.0 的都有,是不是剛好參考到2.0.5.0 而沒有參考到這二個所致?又該怎麼調整?
刪除解決了。原來是我用 .NET Core 做新專案 主控台應用程式,而若用。.NET Framework 就不會了。查了一下他們的 StringInfo 定義,二者所引用的組件是不同的。若用.NET Framework,則其引用的即是 mscorlib 4.0.0.0版本,這就沒問題了。原來果出自它們預設套用的組件上。 南無阿彌陀佛
刪除剛才用WebSite檢驗(新網站),我之前寫的是正確的,只是Console(主控台)無法支援字元,故顯示似不正確爾。程式碼略改如下:
刪除using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.UI;
using System.Web.UI.WebControls;
using System.Globalization;
public partial class _Default : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
//string mystr;
string str = "𧖟厵陳𣡻明𨰻";
//string str = ActiveDocument.Range.Text
StringInfo mystrInof = new System.Globalization.StringInfo(str);
//Response.Write(str.Length);
//Response.Write(mystrInof.LengthInTextElements);
TextElementEnumerator mystrEnum = StringInfo.GetTextElementEnumerator(str);
while (mystrEnum.MoveNext())
{
//string mystr = mystrEnum.Current.ToString();
//Response.Write(mystr);
Response.Write(mystrEnum.Current);
}
//StringInfo.SubstringByTextElements(int);
//System.Globalization.StringInfo.SubstringByTextElements(int, int)
//Console.WriteLine("Hello World!");
////Response.Write("南無阿彌陀佛");
////Response.Write( " " + "南無阿彌陀佛");
//StringInfo mystrInfo = new StringInfo("南無阿彌陀佛");
//Response.Write(mystrInfo.SubstringByTextElements(0, 2));
}
}
這就是逐一條列,也就是能逐一處理漢字的程式了。
顯然您已經比我更厲害了,您問的問題我心中都還沒譜呢!
刪除剛才要再操作才發表表格裡的中文字已經跑掉了,可能與先生您修改了有關吧。還好還保有原圖,是否一併訂正,改為原來如圖的六個中文字呢? 謝謝先生。阿彌陀佛
回覆刪除感謝您的提醒,原來在blogspot中利用 𣡻 輸入的文字只能直接更新,如果切到文字編輯模式時,會被轉換掉,一時不察,造成您的困擾,實在抱歉!
刪除